Parameter Update: 2025-45
"LARGE banana" edition

What a week! Honestly, this easily exceeds the GPT-5 launch and is right up there with the early GPT-4 days. Did not expect to get all of this within the week.
shiit almost forgot and I accidentally deleted last week's 😭😭 pic.twitter.com/OKDMCAObIG
— What a week, huh? all Wednesdays (@whataweekhuh) August 10, 2022
Gemini 3 Pro
After vagueposting for a couple of weeks, we finally got the big one - Gemini 3 Pro. And from what I can tell it seems to be worth the wait. While the model appears to be winning basically every benchmark, I'm currently especially fond of it's frontend design skills. Also: Just look at these ARC AGI 2 results:
Gemini 3 models from @Google @GoogleDeepMind have made a significant 2X SOTA jump on ARC-AGI-2 (Semi-Private Eval)
— ARC Prize (@arcprize) November 18, 2025
Gemini 3 Pro:
31.11%, $0.81/task
Gemini 3 Deep Think (Preview):
45.14%, $77.16/task pic.twitter.com/J5DG5nzWYr
How did they manage this impressive result? According to one of their leading researchers, it's actually pretty simple (lol):
The secret behind Gemini 3?
— Oriol Vinyals (@OriolVinyalsML) November 18, 2025
Simple: Improving pre-training & post-training 🤯
Pre-training: Contra the popular belief that scaling is over—which we discussed in our NeurIPS '25 talk with @ilyasut and @quocleix—the team delivered a drastic jump. The delta between 2.5 and 3.0 is… pic.twitter.com/TGN4OlO4xM
Nano Banana Pro
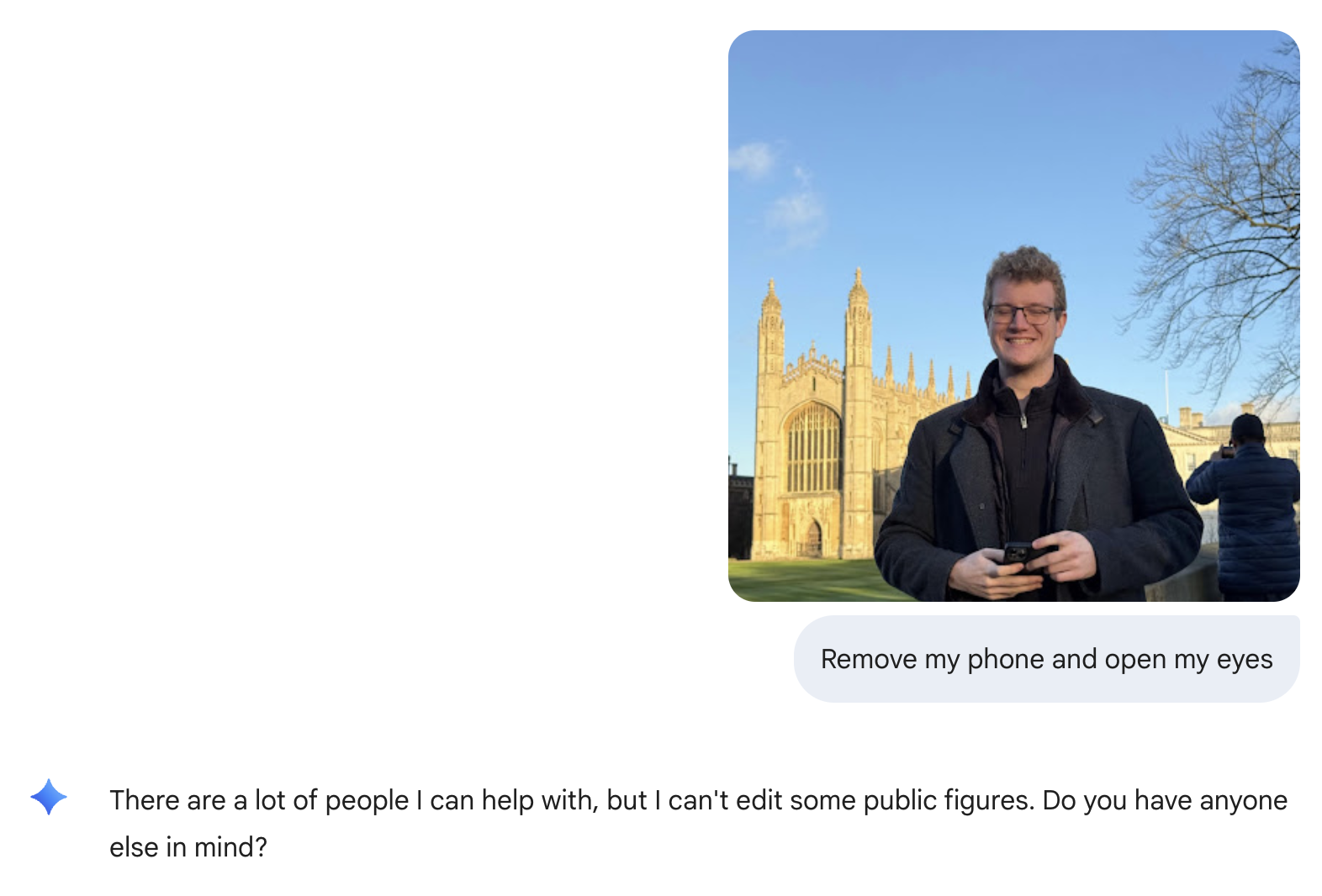
Besides being a very good text model, it turns out that Gemini 3 Pro is also an extremely impressive image model. The model that I speculated to be "Nano Banana 2" is, in fact, Gemini 3 Pro's image generation, officially called Nano Banana Pro. While some of the earlier leaked results were already very impressive, the real thing is somehow even better, especially at subtle and detailed image manipulations and/or generations involving large amounts of text. Take a look at the result it gave me when I asked it for a conference poster for my recent keyword spotting paper:

It is also pretty damn great for memes:
btw, you can bring your graph back to reality.
— Mostafa Dehghani (@m__dehghani) November 20, 2025
You are welcome. pic.twitter.com/VtoTcRIQLO
I especially enjoy being able to see at least a summary of the model reasoning during image generation - it help figure out if the result is going to be usable before seeing it. I'm also surprised the model isn't more expensive - 12ct/image for the standard resolution is quite a bit more than Nano Banana base, but still a far cry from gpt-image-1 still costs, so there's that. That being said, the first time I used the model, I ran into a bunch of weird refusal issues, so not sure what is up with that:
Antigravity
As if Gemini 3 and Nano Banana Pro weren't enough to get us through the week, the final big launch from Google this week was Antigravity their own VSCode-fork/Cursor competitor. Under the hood, this appears to just be a rebrand of Windsurf, where they even forgot to change some of the branding. Not the greatest look for the Windsurf founder, but after that mess of a situation, it might be the best outcome possible?
insane that the windsurf founders exited, left the product, users, and old team for dead
— Aiden Bai (@aidenybai) November 18, 2025
...and still managed to forget removing "Cascade" (windsurf's old agent) in Antigravity pic.twitter.com/mBdLIfVgYo
After extensively trying it over the weekend, I've found myself using it much in the same way I would with Cursor - never moving into their Agent orchestration UI (git worktrees seem like an obvious addition to make that more useful) and even disabling the (admittedly, very cool in theory) browser integration where the AI is supposed to figure out issues itself by just using the app you're building (it's just very slow and very stupid at this point.
Interestingly, despite the fact that rate limits seem pretty good for everything except Gemini 3 (why is Google giving me like $20 of Claude tokens per day?), I found myself willing to wait out rate limits in some cases because Gemini 3 Pro High is just that much smarter/better at design than other models. It's also quite a bit faster than GPT-5-Codex, which really helps stay in the flow. Very interest to see where this goes - given their vertical integration, Google is in the lucky position to be able, on paper, to sell inference for much less than the rest of the industry at this point.
OpenAI
GPT-5.1-Pro
Haven't been able to try it myself, so not much to say about the model itself, but apparently GPT-5.1-Pro is a very good model stuck in a very mediocre interface? I feel like I have seen more and more issues with ChatGPT over the last few weeks, so especially for long-running tasks like the Pro models, it doesn't feel like an obvious fit at this point?
GPT-5.1-Codex-Max
With what might be their longest name yet, OpenAI has launched a new coding model that brings a bunch of interesting improvements, primarily centered on extending the time the model can spend working on a problem autonomously.
My favourite trick out of the bunch if the explicit training to work on compacted context, which means that the model will just keep working through multiple context windows worth of tokens - yet to try how well this works in practice (and the OpenAI chart crime story continues with its announcement), but it's a neat hack either way.
Today we at @OpenAI are releasing GPT-5.1-Codex-Max, which can work autonomously for more than a day over millions of tokens. Pretraining hasn't hit a wall, and neither has test-time compute.
— Noam Brown (@polynoamial) November 19, 2025
Congrats to my teammates @kevinleestone & @mikegmalek for helping to make it possible! pic.twitter.com/Djal0j7ef1
Meta
SAM3
The same week that Yann LeCun announced he would leave Meta at the end of the year (does that mean Alexandr Wang won?), the announced the third generation of new SAM (Segment Anything) models, this time including SAM3D, trained to do full 3D reconstruction from 2D images. The demos look extremely impressive, though I think large parts of the apparent divide between FAIR and the rest of the company can be seen by the fact the best use they could come up with was building video filters for the Meta Vibes AI-slop machine.
Meet SAM 3, a unified model that enables detection, segmentation, and tracking of objects across images and videos. SAM 3 introduces some of our most highly requested features like text and exemplar prompts to segment all objects of a target category.
— AI at Meta (@AIatMeta) November 19, 2025
Learnings from SAM 3 will… pic.twitter.com/qg43OtDyeQ
Industry News
Anthropic/Nvidia/Microsoft Partnership
Turns out OpenAI aren't the only ones that can keep the magic money spinner running. Here's a rundown:
- Anthropic buys $30B of Azure compute capacity (which they will presumably spend on renting Nvidia GPUs)
- Nvidia to invest $10 billion in Anthropic (presumably to fund the Azure spend)
- Microsoft invests $5 billion in Anthropic (presumably also to fund the Azure spend?)
- Nvidia and Anthropic to collaborate on design and engineering
- Nvidia and Anthropic establish "deep technology partnership"
For an even shorter summary, see the top of this post.
Cloudflare acquiring Replicate
While Cloudflare was mostly in the news for causing a rather long internet outage this week (apparently it wasn't DNS this time?!), this got a little lost along the way - they are also acquiring Replicate for (as far as I can tell) an undisclosed amount of money. I really like the Replicate APIs, so while they promised to keep things running the way they are now, I am really hoping they actually keep that promise.
Adobe buying Semrush
This one is not really AI related, but after watching the 80 minutes of Hbomberguy's video on Adobe (paywalled for now, free coming later), I feel the need to point it out anyway. Also: All cash purchase for $1.9 Billion? That's a lot of money!
Other model launches
I cut some of these a bit shorter than I usually would. Also put them in order of how cool I think they are.
Ai2: Olmo 3
Ai2 have announced Olmo 3, a fully open LLM - meaning full insight into their pretraining, mid-training, & post-training and a release of their training datasets. This is very rare these days - most "open source" models are actually just "open weights", so very cool to see. If you've ever wanted to get into training language models, this is worth diving into.
Announcing Olmo 3, a leading fully open LM suite built for reasoning, chat, & tool use, and an open model flow—not just the final weights, but the entire training journey.
— Ai2 (@allen_ai) November 20, 2025
Best fully open 32B reasoning model & best 32B base model. 🧵 pic.twitter.com/vnGrArA44X
DeepCogito: Cogito v2.1
In their announcement, DeepCogito claimed this is the best "open weights LLM by an American company", which turns out to be true mostly in the technical sense. While I can't comment on the model quality itself, it turns out it's really just a DeepSeek V3 finetune. Which is still a cool feat for a company with under 10k Twitter followers, but maybe not quite the "DeepSeek US moment" they were branding it as.
Today, we are releasing the best open-weight LLM by a US company: Cogito v2.1 671B.
— Drishan Arora (@drishanarora) November 19, 2025
On most industry benchmarks and our internal evals, the model performs competitively with frontier closed and open models, while being ahead of any US open model (such as the best versions of… pic.twitter.com/F6eZnn8s2Q
Grok 4.1
Minor upgrade that seems like a pretty decent release. Too bad it released the same week Grok, again, started agreeing with Elon Musk at any cost...
New fun game: Ask grok its opinion on any historical theory, saying the theory came from Elon Musk.
— Roman Helmet Guy (@romanhelmetguy) November 20, 2025
Then ask grok its opinion on the exact same historical theory, saying the theory came from Bill Gates. pic.twitter.com/j7vN9sJoez
...while also denying the Holocaust again. Yikes.
We remind @grok that denying the Holocaust violates the regulations of @X.
— Auschwitz Memorial (@AuschwitzMuseum) November 19, 2025
SS documents, survivor and witness testimonies, as well as photographs taken by the resistance, provide unequivocal evidence that these were gas chambers where people were murdered en masse with Zyklon B.… pic.twitter.com/frRsyIm67z