Parameter Update: 2025-44
"fetch" edition
GPT-5.1 is a nice drop, but I'm still waiting for Gemini 3.0 (wouldn't have expected that to be my priorities a year ago - good on Google for catching up!)
GPT-5.1
Didn't expect to see an OpenAI model drop this week, but this feels pretty explicitly designed to preempt Gemini 3. The GPT-5.1 family of models is a pretty nice update overall - not massively more intelligent, but we got the same efficiency improvements (less thinking for easier questions, more for hard ones) gpt-5-codex incorporated and a more adaptable personality. Personally, I've seen some people on my timeline complain it still feels "2015-era reddit", but I've actually had two experiences this week when the model felt extremely human to talk to and at least one instance of it actually making me laugh. This is not unprecedented, I tend to be pretty easy to entertain, but I still see it as a good sign overall. A bit of a weirdness in how the announcement was handled, though - with no benchmark scores and the API arriving a solid week later.
GPT-5.1 in ChatGPT is rolling out to all users this week.
— OpenAI (@OpenAI) November 12, 2025
It’s smarter, more reliable, and a lot more conversational.https://t.co/SA1Q1GPyxV
Anthropic
Disrupted Cyberattack
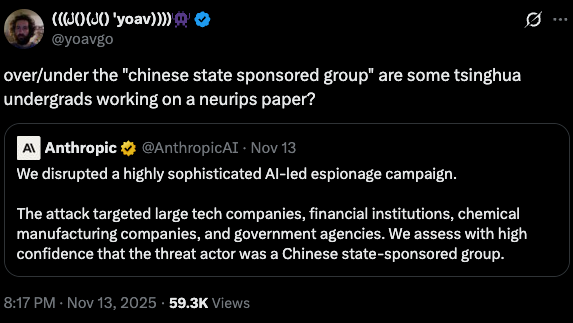
In a slightly cringe blog post, Anthropic disclosed that a threat actor they identify to be "high confidence” Chinese state-sponsored used Claude Code to run a highly automated pentesting operation on over 30 organisations worldwide. While they aren't sharing names, they do note that a few of the intrusion attempts actually succeeded. They also highlight the "jailbreak" the attackers used - they simply told Claude that it was running a legitimate pentest on their own environment and broke the tasks down into a lot of smaller steps the model happily adhered to.
While I am happy this got shut down, I am left with two concerns:
- Does this mean Anthropic is large-scale monitoring the requests people are running through their API? I am very surprised this did not get lost in the noise - their telemetry must be very detailed?
- Open source models are usually very close to proprietary models (or even exceed them in some cases). If any actually serious actor wanted to scale this type of operation, it seems very trivial to just run the same playbook using a local instance of K2-thinking (or, god forbid, any of the dozen intentionally unaligned fine-tunes of other models that anyone can just download)
I don't have a good answer on how to solve this - similar to the bioweapon threat angle AI-security people keep talking about, this seems impossible to prevent without blocking legitimate use cases (Germany has a history of hurting themselves trying to do so), and I think the legality of running these models really shouldn't be touched?
A Chinese state-sponsored threat actor jailbroke Claude into doing real-world cyberattacks.
— Peter Wildeford🇺🇸🚀 (@peterwildeford) November 13, 2025
The AI completed roughly 80–90% of the campaign autonomously, with human operators stepping in only for about 4–6 key decision points.
Targets included major tech companies, banks,… https://t.co/LMYpjP2nqC pic.twitter.com/ejm5iHfZBt
Project Fetch
This one is a bit of a fluff piece, but it's a nice watch anyway: Anthropic ran an experiment, having two teams compete to get a robot dog up-and-running, one with Claude and one without. Obviously the Claude team crushes, but I was surprised to see (1) the also failed the final challenge (autonomy) and (2) their biggest gains were in automating the setup/initial configuration, not in pure code generation.
Nested Learning
For years now, one of the constants of language models has been the differentiation between model weights (updated during training) and in-context learning (information in the prompt, reset per-conversation). This week, Google published a paper on "nested learning" - basically the idea of treating the both of these as "associative memories" - little modules that learn “when I see this, I should recall that”. This is positioned as a counter to catastrophic forgetting - the tendency of LLMs to forget prior information when their weights are fine tuned, as new information doesn’t slam directly into the same single memory store. Instead, it first lives in fast, short-term memories and only gets promoted into slower, more stable memories if it keeps being useful. Strong progress towards continuous learning, and the paper is absolutely worth a read.
Gemini 3 Rumors
While Google has still not officially dropped Gemini 3, the leaks keep piling on, with Google (accidentally?) AB-testing the model in a bunch of products, including their iOS app, and it's increasingly looking like it's going to be very good. Between the impressive Canvas designs and the nano-banana-2 leaks last week, I'd probably not bet against Google right now.
And HERE IT IS GEMINI 3!!!
— Dorksense (@Dork_sense) November 13, 2025
Prompt: Make a neobrutalist webpage, make it extremely creative, as far as possible, push the limits. Add smooth scroll animations, add fancy colors and tailwind css styles. Make it responsive. title of the page is dorksense
Check it out… https://t.co/n3cCzy3fNZ pic.twitter.com/Azk55gPxI6
Even the big man himself got in on the action:
— Sundar Pichai (@sundarpichai) November 14, 2025