Parameter Update: 2025-14
"gpt-4o4-mini-high" edition
OpenAI
While I (quite extensively) made fun of Altman's vagueposting last week, we finally got actual launches this week - nice!
GPT-4.1, 4.1 mini, 4.1 nano
On Monday, we got the latest (and hopefully last) iteration of models within the GPT-4 nomenclature. Teased as "Quasar Alpha" and "Optimus Alpha" in OpenRouter of all places, the GPT-4.1 series is being marketed directly at developers (in the sense that they are useful for developers building stuff with them, not in the sense that they are particularly good at code). In total, we get three model variations, all of which are API-only for now:

- GPT-4.1: Effectively a drop-in replacement for GPT-4o - being both slightly smarter, slightly faster and slightly cheaper. It also brings 1 Million Tokens worth of context limit, which feels like an underrated upgrade. Doesn't seem like the model can do image generation for now, though.
- GPT-4.1 mini: Meant as a drop-in replacement for GPT-4o mini. As the latter was effectively useless for anything but meaningless chit-chat, the large increase in intelligence might actually make this one very interesting.
- GPT-4.1 nano: This is a weird one. The low latency is cool, but can anyone think of a use case that requires less intelligence than 4o mini that wouldn't be better served using a different model? At least it's very cheap!
Slightly hidden away at the end of the stream was the announcement that the launch of these models would also bring the deprecation of GPT-4.5 over the next few weeks. I get that it's a big, expensive model, but having this coincide with the deprecation of GPT-4 in ChatGPT, I can help but feel a bit sad about the shift away from these big base models - there was a class of writing that GPT-4.5 could do that even the new models (which feel distilled from it to some degree) just can't reach.
o3 & o4-mini
After I had a couple of days to mope around about losing GPT-4.5, OpenAI came back with a more promising gift bag of models - o3 (full) and o4-mini. Importantly, this was not a soft launch, with worldwide access to both models being rolled out immediately after the stream (which I always appreciate).
While these two models are tied neck in neck with the Gemini 2.5 Pro in terms of benchmarks, they feel like even more of a step-function improvement in real world usage than Google's model did. So while the models might be similar in pure intelligence, o3 in ChatGPT is a much more compelling system right now. My initial impressions of o3-full were overwhelmingly positive. Going from GPT-4o to o3 feels like the type of step up GPT-3.5 to GPT-4 was. It's also the first model that doesn't devolve into nonsense on some of the more theoretical/research-y stuff I do.
Now, that statement comes with some caveats, mostly based around the fact that o3 was fine-tuned to works as an agentic model with access to tools like web search and code interpreter. This means that, when these tools are disabled, the model suffers quite massively from hallucinations that can make it perform not quite right at coding.
Unfortunately, I have since run through my weekly prompt quota of o3. o4-mini-high also feels extremely smart (and substantially better than o3-mini, which is replaces), but it does lack that ✨spark✨ that o3 has.
... in other news
The release of the new o-series models also gave us the Codex CLI, an open source alternative to Claude Code. Seems cool, haven't gotten around to trying it though.
OpenAI appears to be getting serious about the developer market, as they seem to be considering acquiring Windsurf (for $3B!) after discussions with Cursor fell through.
Gemini 2.5 Flash
Just when you thought Google might let OpenAI sit this one out, they came back with Gemini 2.5 Flash, the faster but slightly less intelligent cousin of their Gemini 2.5 Pro behemoth. While I would argue that there is some amount of benchmark-maxxing going on / intelligence that is being underrepresented by these benchmarks, this release does once again give Google the edge when it comes to owning the cost/intelligence frontier:
Correction: Yesterday I missed Gemini 2.5 Flash (no‑thinking)
— Pierre Bongrand (@bongrandp) April 18, 2025
TL;DR: ~95% of the time, Google’s Gemini models offer the best performance-per-dollar
It’s bloody out there, and it’s OpenAI's blood https://t.co/lhcGppZUab pic.twitter.com/a9CRVbj4dV
It's also, to my knowledge, the first time Google has been able to snipe an OpenAI announcement like this, so hat's off to them (this has been a long time coming for OpenAI, who are legendary dicks about this kind of stuff).
DolphinGemma
Turns out language models are really good at... modelling language. While we have seen much progress on under-represented languages over the last years, we're now also seeing this expand to non-human language. In collaboration with the Wild Dolphin Project, DeepMind has fine-tuned a version of Gemma 3 on labeled Dolphin noises, creating a model that can run on Pixel phones to both understand Dolphin sounds and produce novel sounds that, with some training on the Dolphin side, may be understood by them. Neat!
Meta
After LeCun told the world he was bored with LLMs after the disappointing Llama-4 launch (fair, but also - what else was he gonna say?), I was expecting FAIR to drop some more non-LLM stuff soon. Now, that has happened. In their usual style, we got a while bunch of research at once:
- Meta Perception Encoder: A large-scale vision encoder that excels across several image & video tasks.
- Meta Perception Language Model: A fully open & reproducible vision-language model designed to tackle visual recognition tasks.
- Meta Locate 3D: An end-to-end model for accurate object localization in 3D environments
- Model weights for 8B-parameter Dynamic Byte Latent Transformer (working towards tokenizer-free language models)
- Collaborative Reasoner: A framework for evaluating & improving collaborative reasoning skills in language models (this might hint at the "Llama-4 Reasoning" people are speculating about?)
Other stuff
Richard Sutton: "Welcome to the Era of Experience"
Richard S. Sutton, one of the founders of modern reinforcement learning, has proven prophetic a few times, most legendarily (at least in my circles) with his "Bitter Lesson" paper in 2019. This week, he has dropped "Welcome to the Era of Experience", outlining his view on the future direction of the field.
While some of the ideas seem a little out there (and Twitter is busy arguing that it's only real RL if done in the Reinforcement region of France or something), most of the technical foundation he talks about is already feasibly today (or will be very soon) and it feels undeniable that there is some truth to his thoughts.
The core proposition is as follows: While The Bitter Lesson argued that a simple architecture with more data/compute will always outscale complex/clever architectures eventually, The Era of Experience argues
- Modern LLMs have scaled primarily by scaling pre-training in human data.
- We’re now running out of that data, so the next step is collecting data by having the model works as an agent, experiencing an environment
- This will require longer interaction episodes (long-running tasks vs. short Q&A)
- The reward function will be composable and updatable over time. It will not depend on human prejudgement.
- Human-like chain-of-thought reasoning is a stepping stone to having models self-reason (as human reasoning is limited to human world views)
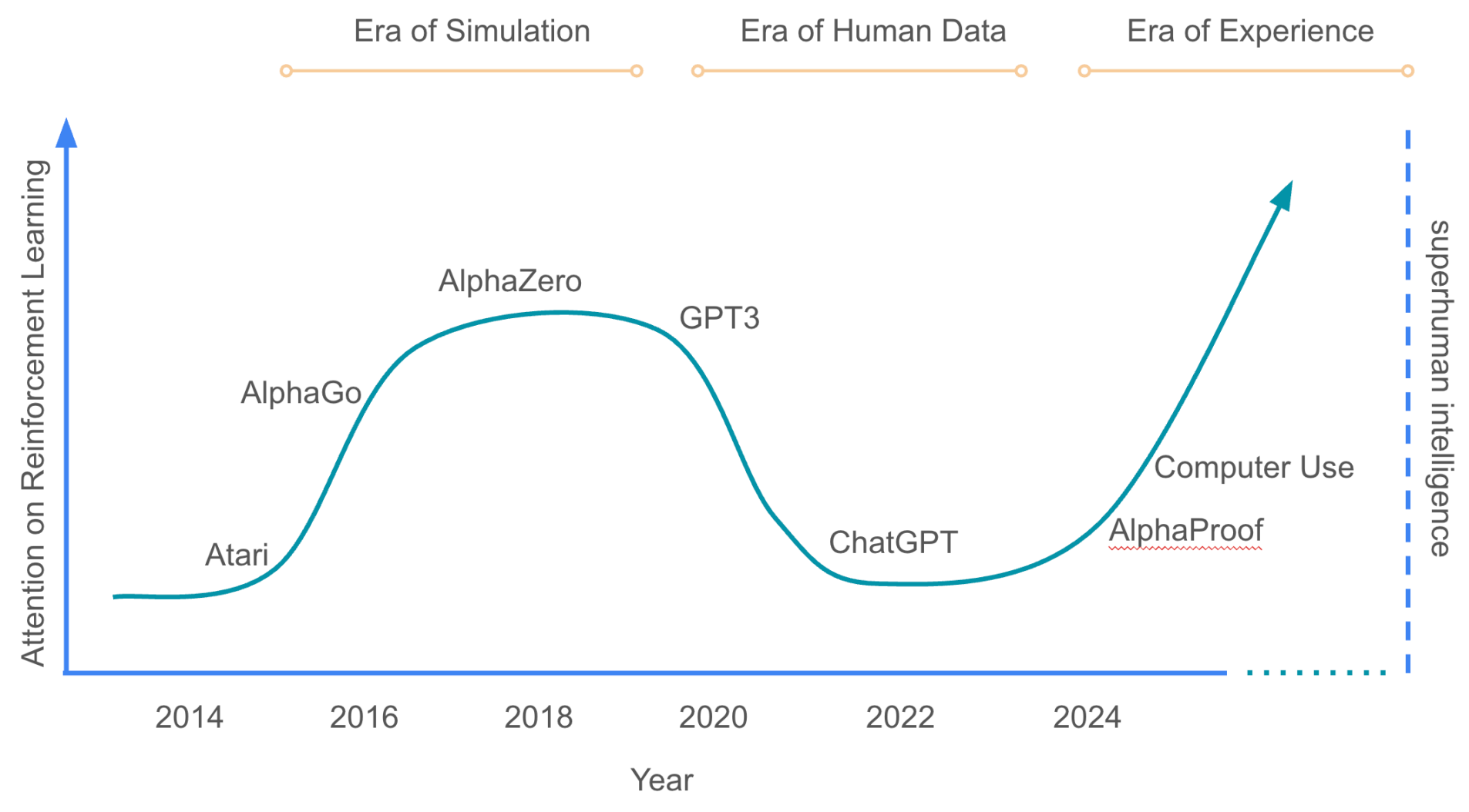
While some of this is not a fundamentally new thought (scaling LLM reasoning with RL has been done for a while), it is the first time I have seen these ideas put together succinctly, and there is certainly an art in what Sutton has done here. Well worth a read.
Stanford: CS336
In case anyone want to get really into the weeds on building language models, Stanford has just launched a new class for you, fully available online. This is, to my knowledge, the most comprehensive class on these topics offered for free by a traditional university.
Goodfire
Mechanistic interpretability startup Goodfire has raised a $50 Million Series A, with investors notably including Anthropic. The core idea: Take the research that has given us Golden Gate Claude and use it to deterministically tweak model behavior. Mostly putting it in here as I found it surprising Anthropic isn't content just doing this stuff in-house.